Custom Psychometric Instrument or Off-the-Shelf? The Build-vs-Buy Decision
Filed under: Psychometrics · Talent Development
The most common question I get from HR and L&D leaders evaluating psychometric assessment is whether to use Big Five or commission something custom. The framing of the question is usually wrong. Big Five and custom instruments do not compete on the same axis. They answer different questions, and the right choice falls out of which question the buyer actually has.
Two recent client engagements I designed make the contrast concrete. One organization, a Fortune 1000 enterprise IT services firm, used a Big Five-derived strengths model and got useful findings. The other, a fast-growing consumer-tech company, used a custom five-value instrument and got useful findings. Same outcome on the engagement, different routes. The difference between the two cases is the difference that should drive the build-versus-buy decision in any organization considering this work.
This post is the third and final entry in a three-part series. Part 1 covered the four-archetype convergence in cluster analyses run on the data from these two engagements. Part 2 covered the structural equation model results that showed years of experience predicting two specific traits in each study and not the others. Part 3 is the methodological question that sits underneath both: when does a custom instrument earn its longer build cycle, and when is off-the-shelf the right call?
Table of Contents
- The wrong framing
- Organization A: when off-the-shelf personality was the right call
- Organization B: when custom was the only viable route
- The decision rule
- The cost asymmetry buyers underestimate
- What good buyer questions look like
The wrong framing
Most buyers approach the build-versus-buy question through one of three frames: which approach is more rigorous, which is more expensive, or which is faster to deploy. All three frames miss the actual question.
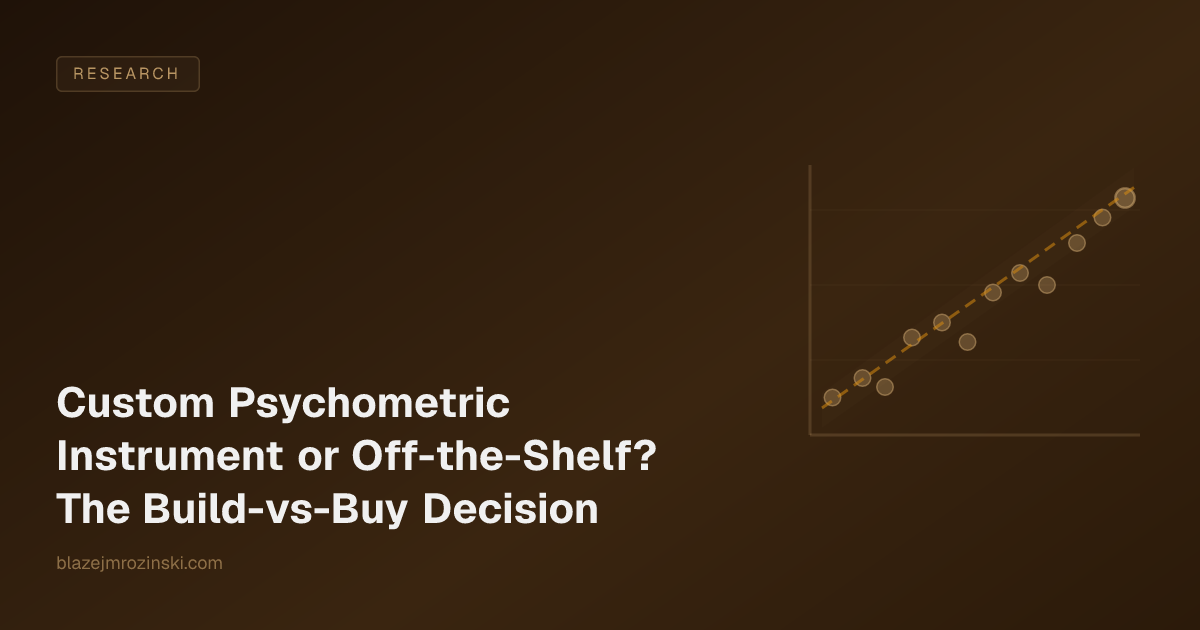
The actual question is whether the constructs the buyer needs to measure are well-served by an existing well-validated instrument. If the constructs are standard ones, conscientiousness, openness, agreeableness, emotional stability, extraversion, or any of the well-validated facets of those, then off-the-shelf instruments built on Big Five or HEXACO or one of the other major frameworks are usually the right answer. The rigor is well-established, the norms exist, the deployment is fast.
If the constructs the buyer needs to measure are not standard, meaning they are specific to the organization’s operating language, role definitions, or values architecture, then off-the-shelf instruments do not measure them directly. Big Five facets are close to many organizational constructs but never identical to them, and the gap between “close” and “identical” is where the decisions made on the basis of scores get fuzzy.
Saying that more plainly: off-the-shelf is right when your constructs are already named and validated in the literature. Custom is right when the constructs you care about are named and validated in your own operating language but not in the standard psychometric literature. The decision is about construct fit, not about rigor or cost.
Organization A: when off-the-shelf personality was the right call
Organization A’s engagement used a Big Five-derived strengths model assessing eight competencies: Self-Discipline, Directness, Cooperativeness, Curiosity, Self-Efficacy, Adaptability, Sociability, and Initiative. All eight are standard facets in the broader Big Five literature with established validation evidence and population norms. The choice to use this instrument rather than a custom build was right for three reasons.
Construct fit. The competencies the organization cared about for its talent development decisions were all well-served by Big Five-adjacent facets. The internal language used to describe high-potential employees, leadership candidates, and development priorities mapped cleanly onto the available facets. There was no construct-language gap that custom design needed to bridge. A custom instrument would have measured the same things under different names, with the same scoring distributions, at higher cost and longer timelines.
Sample size economics. Roughly 500 employees across multiple role categories. Plenty of variance for population-level inference and cluster identification on the standard constructs. A custom instrument would have needed similar sample sizes for proper validation, with no incremental return because the construct space was already covered.
Decision criteria. The organization’s L&D, talent development, and talent acquisition teams needed instruments that could feed multiple program-specific decisions. Standardized, well-validated constructs were easier to integrate across programs (high-potential, senior leadership, junior development) than custom-defined constructs would have been. The same Curiosity score informed L&D budget allocation, leadership pipeline screening, and onboarding personalization without translation work between programs.
What the engagement did add that goes beyond what off-the-shelf alone provides: the layered architecture on top of the standard instrument. The same competency scores fed four distinct programs with different decision criteria, including a high-performance program for women and a junior development pipeline. The architecture was custom. The constructs were standard. That distinction matters because it is the part of the engagement that did not exist in any vendor catalog. The instrument layer was bought; the program layer above it was built.
Organization B: when custom was the only viable route
Organization B’s engagement used a custom five-value instrument with the values translated to construct labels as Resilience, Growth Mindset, Bias for Action, Ownership, and Trust-Building. The construct translations are accurate to what each value measures. The brand-specific labels in the original instrument are different and identify the company, so they live in the internal documentation rather than in this post. The choice to build custom rather than buy off-the-shelf was right for three reasons.
Construct fit failure. The five values that mattered to the organization are not Big Five facets. Resilience overlaps with low Neuroticism but is not identical; the workplace-specific resilience the company cares about includes elements of stress tolerance, recovery from setbacks, and willingness to operate under ambiguity that a generic emotional-stability score does not capture. Bias for Action draws from Conscientiousness but is more specifically about decision speed than about discipline or organization. Trust-Building overlaps with Agreeableness but is about the active behavioral skill of building trust with peers and customers, not about being trusting as a personality default. The construct-language gap was real and not bridgeable through relabeling Big Five facets.
Format failure on Likert. The Big Five literature is dominated by Likert-scale instruments. Likert formats produce ceiling effects on prosocial values items, the failure mode where everyone rates everyone as “agree” or “strongly agree” because the items are socially desirable. A Likert measurement of “I value teamwork” or “I take ownership of my work” produces distributions piled at the top of the scale and very little discriminating variance between candidates. The instrument needed forced-choice formats, ranking, and situational-judgment items in combination to recover discriminating variance. That kind of multi-format assessment is a custom build feature, not a default vendor instrument configuration.
Decision criteria. The hiring managers reading the output were not psychometricians. They needed scores expressed in their own operating language, the language the company already used internally to describe what good performance looked like. A score profile saying “high in Bias for Action and Ownership, moderate in Trust-Building” produced better hiring conversations than a score profile saying “high in Conscientiousness facet 3 and Self-Efficacy, moderate in Agreeableness facet 2” would have. Construct-language alignment with the buyer audience reading the output is a feature of the design, and it is one that off-the-shelf instruments cannot provide because they cannot anticipate every buyer’s internal language.
What the off-the-shelf path would have lost: the ceiling-controlled discriminating variance, the construct-language alignment with the company’s operating model, and the situational-judgment layer that anchored abstract values in concrete behavioral evidence. Each of those is recoverable in principle through clever scoring or adapter layers around an off-the-shelf instrument, but the recovery is more expensive than the original custom build.
The decision rule
Generalized from the two cases, the build-versus-buy decision rule is straightforward.
Off-the-shelf is the right call when:
- The constructs you need to measure are well-served by an established framework (Big Five, HEXACO, or a validated narrow instrument such as the Watson-Glaser, NEO-PI-3, or California Psychological Inventory).
- Your decision criteria can be expressed in standard psychometric language without distortion.
- Your sample sizes do not justify the validation cost of a custom instrument.
- Speed-to-deployment matters more than construct-language alignment with buyer audiences.
- You do not have a custom values, competency, or culture model that the instrument needs to reflect.
Custom is the right call when:
- Your operating language uses constructs that do not map cleanly onto standard frameworks.
- Your decision criteria require construct-language alignment with the buyer audience reading the output (hiring managers, executives, L&D leaders).
- Standard instruments produce ceiling effects, social-desirability response bias, or other measurement failures on your specific population or use case.
- Your sample sizes support proper validation, typically 200 to 500 respondents minimum per construct for stable estimates.
- The decisions you are supporting are consequential enough to justify a multi-week to multi-month build cycle.
Hybrid is the right call when:
- Some of your constructs are standard and some are custom. Use off-the-shelf instruments for the standard ones and custom instruments for the gap. Many enterprise programs end up here.
The honest version of the rule: this is rarely a clean either-or in real engagements. The Organization A engagement was off-the-shelf in its constructs but custom in its program architecture. The Organization B engagement was custom in its constructs but reused standard validation methodology. The build-versus-buy framing implies a binary that the actual practice does not respect.
The cost asymmetry buyers underestimate
The cost discussion is where most build-versus-buy decisions go wrong, because buyers compare upfront cost rather than total cost over the lifecycle of the instrument.
Off-the-shelf cost structure. Vendor licensing fees per seat or per assessment. Setup time of weeks rather than months. Norms and validation already in place, so no in-house psychometric expertise is needed for that part of the work. The upfront cost is predictable and modest.
Custom cost structure. A construct definition phase including job analysis interviews, theory work, and stakeholder alignment. Item development, including format selection and item writing for each construct. Pilot testing on a smaller sample, often 50 to 100 respondents. Validation studies on a larger sample, typically 200 to 500 respondents minimum for stable estimates. Score-key derivation. Norming. Feedback architecture design. Reporting and integration. The work runs months rather than weeks, and the upfront cost is several multiples of an off-the-shelf license.
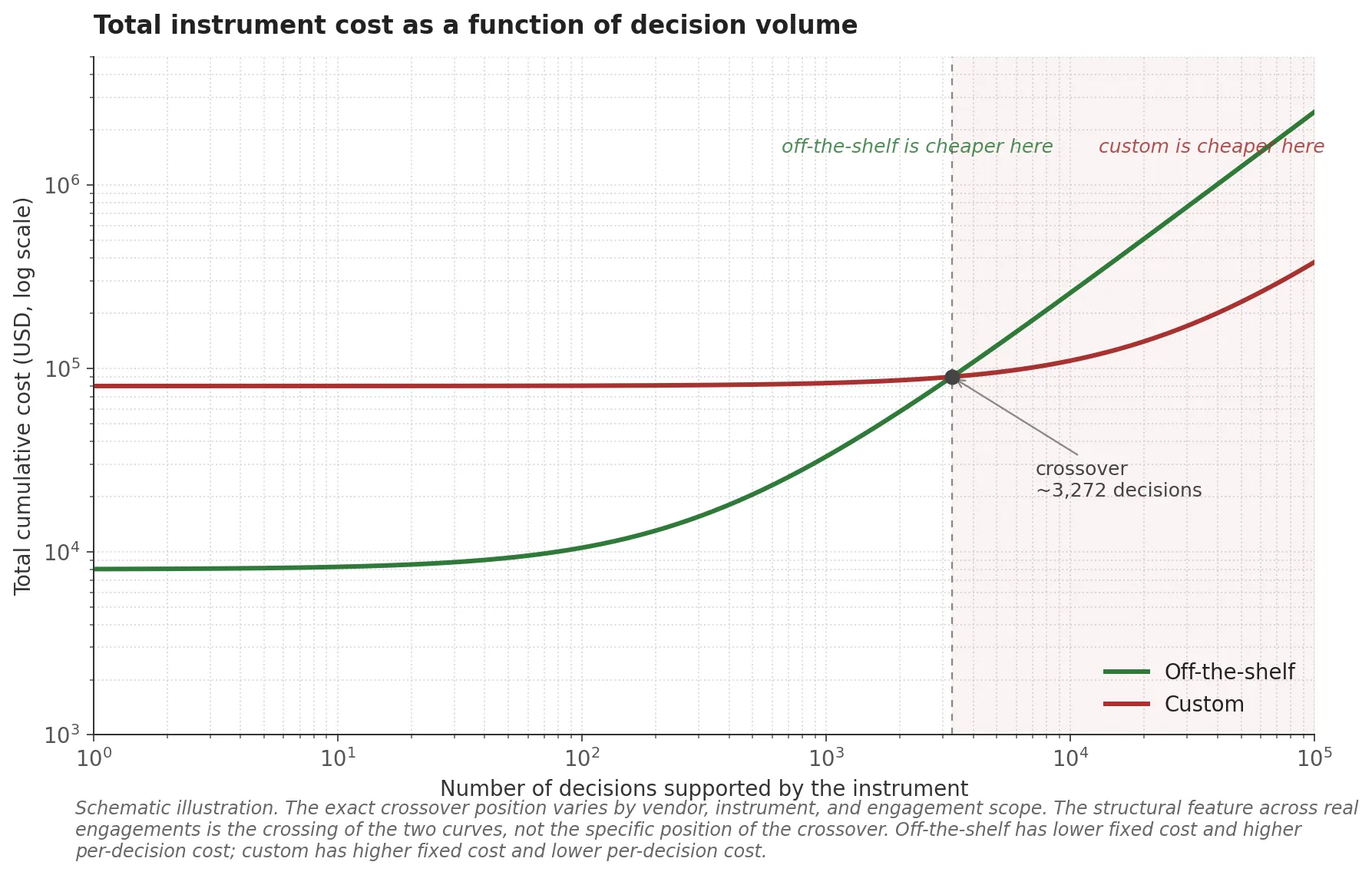
The asymmetry that matters: off-the-shelf has predictable upfront cost and no construct-language alignment work in the design phase, but the construct-language alignment work will get done somewhere. If it does not happen during instrument design, it happens later, in interpretation. Hiring managers translate the standard outputs into their own language ad hoc, with inconsistencies and judgment errors that scale linearly with the number of decisions made on the basis of the scores. Across enough decisions, the cost of those errors exceeds the upfront cost of building a custom instrument that did the alignment work once and consistently.
Custom has higher upfront cost and longer timelines, but moves the construct-language alignment work into the design phase where it is done once, defensibly, and consistently across all downstream decisions.
For one-off decisions (one role, one cohort, one program), off-the-shelf almost always wins on total cost. For recurring decisions (10,000 candidates per year, multiple programs over multiple years), custom often wins on total cost when the construct-language alignment work is properly accounted for. The chart below illustrates this dynamic. The exact crossover point depends on the specific cost structure of the vendor and the engagement scope, but the shape of the two curves is consistent across most build-versus-buy comparisons I have seen.
What good buyer questions look like
The practical close. The questions a serious HR or L&D leader should be asking before this build-versus-buy decision, and the order to ask them in.
1. What construct do I actually need to measure? State it in two pages. If you cannot state it clearly in two pages, you are not yet ready to choose between off-the-shelf and custom. Spend the early budget on construct definition work rather than instrument procurement. The construct definition work is the bottleneck that determines everything downstream.
2. Does an existing well-validated instrument measure that construct directly? Not “approximately”, not “close enough”, but directly. If yes, off-the-shelf is the default. If no, custom is the path. The instrument-procurement choice should follow the construct-definition answer, never lead it.
3. What decisions will the scores support, and in whose hands? If the scores will be read by hiring managers in your operating language, construct-language alignment matters and weighs toward custom. If they will be read by I/O psychologists or HR data analysts who can translate, standard psychometric language is fine. The audience reading the output is a determining factor that buyers usually do not surface explicitly.
4. What is my sample size? Custom instruments need validation samples. Below 200 to 300 respondents per construct, custom validation is unstable and the resulting score-key derivation is unreliable. Off-the-shelf instruments come pre-validated, which means they work at any sample size, including the small ones where custom would fail.
5. What is my decision frequency and stake? One-off, low-stakes decisions do not justify the custom cost. Recurring, high-stakes decisions usually do. The cost asymmetry from the previous section is what determines the answer here.
If you are not sure which side of these questions you fall on, the right next step is to talk to a practitioner who has built both. The conversation is usually shorter than buyers expect. Sometimes the answer is custom and the engagement starts immediately. Sometimes the answer is “your constructs are well-served by an existing instrument and you do not need me, here is a list of vendors who do this well”. Both answers are honest. The framing of the question as “which is better” is what produces bad decisions; the framing as “which fits your constructs and your decisions” is what produces good ones.
If you are weighing this question for your own organization, I am reachable through the contact form. The methodology context for all of this lives in the earlier post on what custom psychometric work actually is, and more on the platform side of this work lives at Gyfted. Part 1 and Part 2 of this series cover the substantive findings from the two engagements that anchored the build-versus-buy contrast in this post.